 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Statistical Language Learners: Experiments on Noun Compounds
Sep 25, 1996
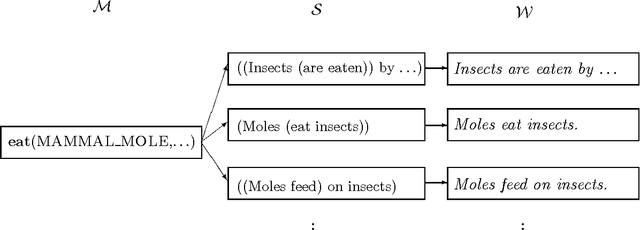

The goal of this thesis is to advance the exploration of the statistical language learning design space. In pursuit of that goal, the thesis makes two main theoretical contributions: (i) it identifies a new class of designs by specifying an architecture for natural language analysis in which probabilities are given to semantic forms rather than to more superficial linguistic elements; and (ii) it explores the development of a mathematical theory to predict the expected accuracy of statistical language learning systems in terms of the volume of data used to train them. The theoretical work is illustrated by applying statistical language learning designs to the analysis of noun compounds. Both syntactic and semantic analysis of noun compounds are attempted using the proposed architecture. Empirical comparisons demonstrate that the proposed syntactic model is significantly better than those previously suggested, approaching the performance of human judges on the same task, and that the proposed semantic model, the first statistical approach to this problem, exhibits significantly better accuracy than the baseline strategy. These results suggest that the new class of designs identified is a promising one. The experiments also serve to highlight the need for a widely applicable theory of data requirements.
Conceptual Association for Compound Noun Analysis
Sep 11, 1996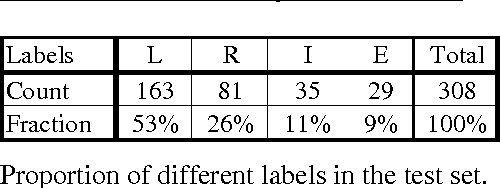

This paper describes research toward the automatic interpretation of compound nouns using corpus statistics. An initial study aimed at syntactic disambiguation is presented. The approach presented bases associations upon thesaurus categories. Association data is gathered from unambiguous cases extracted from a corpus and is then applied to the analysis of ambiguous compound nouns. While the work presented is still in progress, a first attempt to syntactically analyse a test set of 244 examples shows 75% correctness. Future work is aimed at improving this accuracy and extending the technique to assign semantic role information, thus producing a complete interpretation.
* 3 pages, postscript only, replaced because original postscript version incompatible with some printers
Corpus Statistics Meet the Noun Compound: Some Empirical Results
Sep 10, 1996

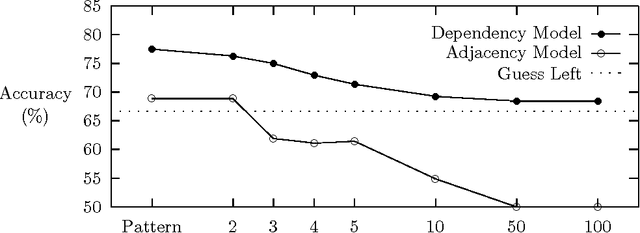
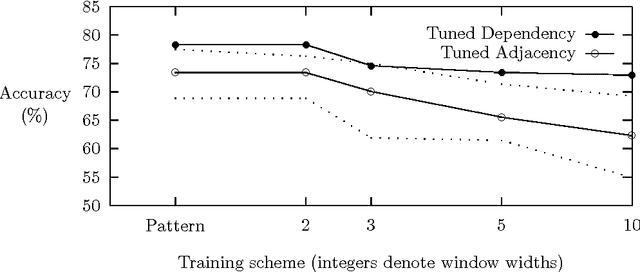
A variety of statistical methods for noun compound analysis are implemented and compared. The results support two main conclusions. First, the use of conceptual association not only enables a broad coverage, but also improves the accuracy. Second, an analysis model based on dependency grammar is substantially more accurate than one based on deepest constituents, even though the latter is more prevalent in the literature.
* 8 pages, 5 figures, uses modified version of aclap.sty, replaced because old version failed to TeX properly
Conserving Fuel in Statistical Language Learning: Predicting Data Requirements
Sep 07, 1995
In this paper I address the practical concern of predicting how much training data is sufficient for a statistical language learning system. First, I briefly review earlier results and show how these can be combined to bound the expected accuracy of a mode-based learner as a function of the volume of training data. I then develop a more accurate estimate of the expected accuracy function under the assumption that inputs are uniformly distributed. Since this estimate is expensive to compute, I also give a close but cheaply computable approximation to it. Finally, I report on a series of simulations exploring the effects of inputs that are not uniformly distributed. Although these results are based on simplistic assumptions, they are a tentative step toward a useful theory of data requirements for SLL systems.
* 8 pages
How much is enough?: Data requirements for statistical NLP
Sep 07, 1995
In this paper I explore a number of issues in the analysis of data requirements for statistical NLP systems. A preliminary framework for viewing such systems is proposed and a sample of existing works are compared within this framework. The first steps toward a theory of data requirements are made by establishing some results relevant to bounding the expected error rate of a class of simplified statistical language learners as a function of the volume of training data.
* 9 pages
A Probabilistic Model of Compound Nouns
Sep 06, 1994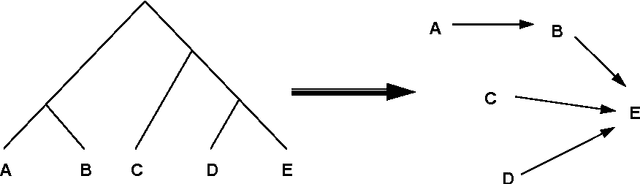
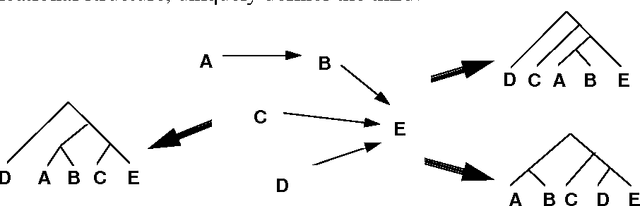
Compound nouns such as example noun compound are becoming more common in natural language and pose a number of difficult problems for NLP systems, notably increasing the complexity of parsing. In this paper we develop a probabilistic model for syntactically analysing such compounds. The model predicts compound noun structures based on knowledge of affinities between nouns, which can be acquired from a corpus. Problems inherent in this corpus-based approach are addressed: data sparseness is overcome by the use of semantically motivated word classes and sense ambiguity is explicitly handled in the model. An implementation based on this model is described in Lauer (1994) and correctly parses 77% of the test set.
* 9 pages, uuencoded compressed postscript, please ignore any undefined command error at end